Foundations – What is a database?
Data is around everything that we do in modern life. From checking your email, to visiting the grocery store, our devices are constantly collecting information. We even use data in our day-to-day lives as well. When was the last time you made a purchase without first comparing the prices of other items? Using data-driven decisions, companies and individuals can find more success and reward in their goals and ambitions.
The problem is that at the enterprise scale, data is massive. If you have one million customers and each customer has one hundred different things that are being tracked, and then some of these events are repeating and based around time, then the amount of information starts to quickly build up. Think about transactions at a store even – a business might want to calculate sales on every Friday, but how do we keep track of the time something was purchased? More data.
If we put all of this data into an excel spreadsheet, how many different pages would there be? How many different columns? What does each row represent? If you have a single customer that purchase multiple times a month, is that kept in one row or in one column or in a different page altogether? How would you even begin to parse all this information?
This is where we enter databases. A few commons ones are SQL (pronounced sequel as it’s origins were that it was the successor, or sequel, to previous designs before it) and NoSQL (Graph, Key-Value, Columnar, and Document Oriented). There are multiple different implementations of SQL databases and multiple different implementations of NoSQL databases. For the purposes of this discussion, we will focus on SQL databases.
What is SQL?
SQL is a database structure using a combination of tables and columns which can be access quickly using a technique called querying. Often times a large SQL database will hold multiple tables and these tables will all be connected with id columns. For instance, if there is a customer who has information stored in multiple tables, we would have an unique customer_id column. This column could be used to connect a row in a table that stores their address, to a row in a separate table that stores their purchases.

Why do we separate the information into distinct tables? In doing so, we can isolate the information that is pertinent to other information (i.e. purchases with product price, product quantity, or purchase date). This can avoid unnecessary processing times as the computer has fewer items to parse through when you run a SQL query. We won’t get into the specifics of how a query works, but know that less data to check means faster processing. By separating the tables, we can query only the tables that we need, and not all of the data at once.
However, there becomes an issue. The more separate the data is into different tables, the more complicated it can become to find and search for the information because you then need to know which tables hold the information you need and then which id’s connect the tables you have. This increases the developers “cognitive overhead.” With this in mind, database design is about developing a structure that connects the information in an understandable and distinctive way while not being overly complex for the human that has to eventually query it.
Considerations like the amount of data being stored, the amount and size of queries being ran, and the necessity/use-case of the information can all effect the overall design that would be best for the data at hand.
Database Designs
With these things in mind, there are a few overarching considerations for how data should be stored and then there are more specific design considerations as well.
Often times data will either be stored in what is referred to as a “data lake” or a “data warehouse.” To summarize the two quickly, a data lake is largely unstructured, holds massive amounts of data, and is slow to query/parse. Conversely, a data warehouse is more structured, generally contains less data, and is much quicker to parse. Additionally, data lakes can often be better if the information being stored needs to be transmitted to a machine learning model because models take a lot of information to work (that’s that AI buzz word) for further analysis.

Inside of structured SQL data, we can design our table connections in different ways. If you want the least amount of work in building queries, but the slowest query time, all the data could be kept in a single SQL table. However, in most cases, this data is split into multiple tables and the decisions on how to split the data can vary.
B-Tree Clusters
A database can be designed with a root table in mind which expands downward like a family tree. The root table can connect to level 1 tables through a unique id, level 1 tables can connect to level 2 tables, level 2 to level 3, and so on until no more tables are needed. You might hear the lower levels referred to as branches or leaves.
What are the benefits? Information is easily structured and often times it is easy to understand how to connect from one table to another. However, if you want information from the lowest level, the person querying has to connect multiple tables in order to get access to the bottom level of information.
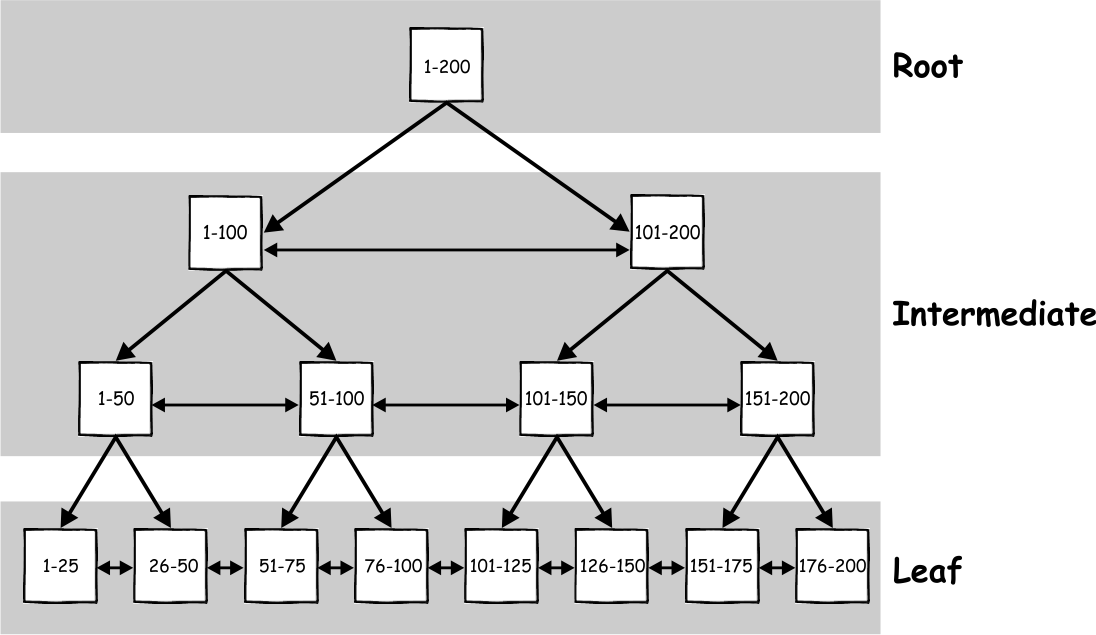
Snowflake Designs
In the Snowflake, tables spread outward from the center like a snowflake. This way if you want to find out information about a customer, you can link to their purchases_id, their personal_information_id, their call_records_id, or any other table related to them all from your root table.
You might find a slightly less complicated version of this referred to as a “Star Schema” which is practically the same thing except that snowflakes have multiple levels of data information whereas a star just has the one level.

These are both good ways of storing data that can minimize the amount of table connections needed from a B-Tree design. The downside is that for every table connection, you need a new distinctive id to match the tables to each other. This add complexity and increases the storage space needed to store the same data. However, it can be much easier to query than a B-Tree, and a Star is generally going to be even easier to query than a Snowflake because there is only the one level of table separations to connect to.
Snowflakes are generally good if you have smaller subsections to connect – for instance, there might be a city with data as the root. One branch might store information like different libraries in the city. Off of that could stem information about different books and authors in the library, then off of authors might stem information about different publishers for those authors. This allows for multiple information to be stored under a single connection in an easier to understand structured manor.
Conclusions
Overall, there are many different database designs out there and this only barely scratches the surface. It is import to take away that the design that best suits your needs is dependant on many factors like the amount of data being stored, the velocity of the data (speed of accumulation), the type of data, and the use case of the data.
Once you have a good means of storing and accessing the data, however, these design implementations can make dramatic impacts on business decisions and results, and they are the backbone to our ever evolving world that we live in today.
One response to “INTRODUCTION TO DATABASE DESIGNS”
Hi, this is test comment – feel free to add your own!