This was a project Integrating a full end to end data pipeline. I used Apache Airflow for the control flow and dependency manager. My process DAG (Directed Acyclic Graph) which determined the necessary dependencies looked like this.
- Ingest CSV file into a Google Cloud Storage Bucket
- Create an open database on Google Big Query
- Load the CSV from the GCS bucket into Big Query
- Check for data quality in Big Query with SODA
- Transform the table into dimension tables using DBT (data build tool)
- Check again for data quality
- Start the second DAG (having all of this in one DAG took too long for my system, so I seperated them out while creating a dependency between the two DAGs)
- Transform the data once more into reporting metrics using DBT
- Check the data one last time using SODA
You can get an idea as to what the DAG looked like from the below graphs:
Retail DAG

Retail_Cont DAG
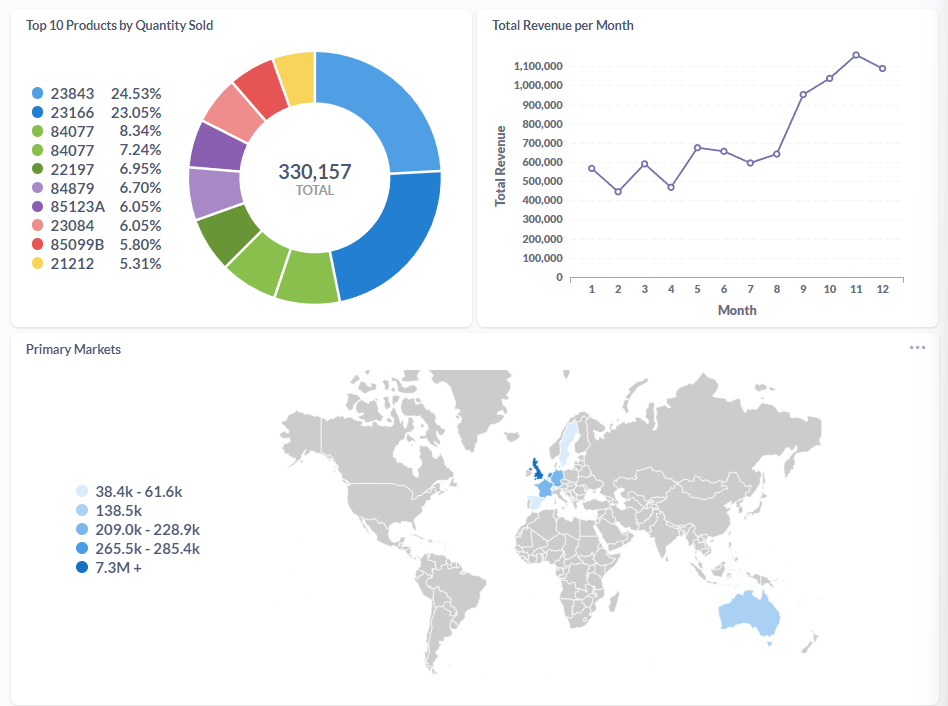
After performing these steps in the pipeline, I created a visualization using Metabase to show the data for potential stake holders. You can see that dashboard below. (This data is sample data from Kaggle)
All of this work can be seen in my GitHub at the following link: https://github.com/c-crowder/retail_pipeline